在开发中 Reids 是我们经常使用到的 NoSql 之一, 在生产环境中, 在某些特定的情况下 (例如: 给开发人员使用的只读库) 需要引入 Redis 的集群方案. Redis 支持三种集群方案: 主从复制模式、Sentinel (哨兵) 模式、Cluster 模式

准备三台虚拟机用于模拟
Redis集群环境, 系统环境:Ubuntu Server 18.04
安装 Redis Server 和 Redis Cli
1 | # https://timelate.com/archives/install-redis-on-ubuntu.html |
主从复制模式
主从复制模式下包含一台主数据库 (master) 和最少一台从数据库 slave. slave 启动后, 向 master 发送 SYNC 命令, master 接收到 SYNC 命令后通过 bgsave 保存快照 (RDB 持久化), 并使用缓冲区记录保存快照这段时间内执行的写命令; master 将保存的快找文件发送给 slave, 并继续执行执行的写明了; slave 接收到快照文件后, 加载快照文件并载入数据; master 在快照发送完成后开始向 slave 发送缓冲期的命令, slave 接收命令并执行, 完成复制初始化. 此后 master 每次执行一个写命令都会同步发送给 slave, 保持 master 和 slave 之间的数据一致性.
修改 master 的配置文件 sudo vim /etc/redis/redis.conf 并重启服务 sudo systemctl restart redis-server
1 | bind 0.0.0.0 # 绑定监听的IP 0.0.0.0允许所有IP访问 |
修改 slave 的配置文件 sudo vim /etc/redis/redis.conf 并重启服务 sudo systemctl restart redis-server
1 | bind 0.0.0.0 # 绑定监听的IP 0.0.0.0允许所有IP访问 |
master 和 slave 都配置后之后, 进入 master 写入一条数据, 立即访问 slave 查看, 或通过 info replication 命令也可以看到当前机器的主从状态
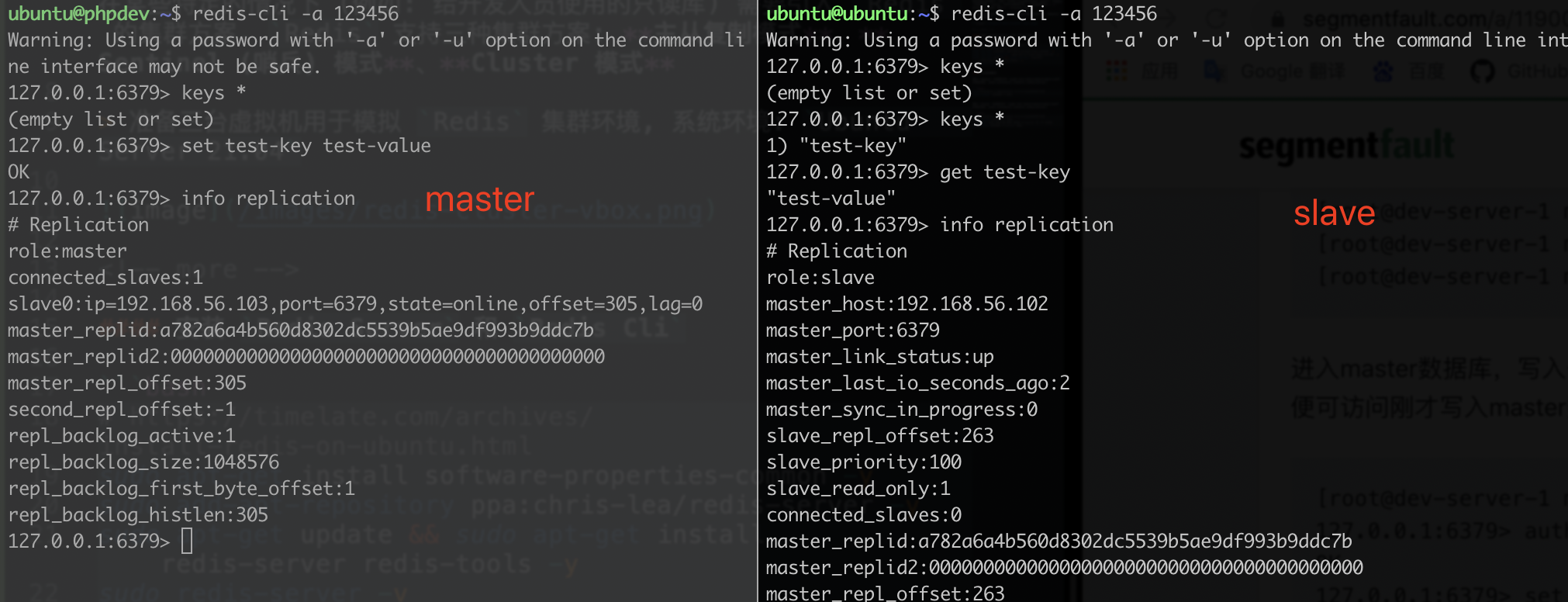
主从模式下
master和slave之间的同步是以非阻塞的形式进行的, 同步期间, 客户端仍然可以提交查询和更新请求
主从模式不具备自动容错和恢复功能,master或slave宕机都有可能导致客户端请求失败; 且难以支持在线扩容,Redis的容量受限于单机配置
Sentinel (哨兵) 模式
哨兵模式基于主从复制模式, 只是引入了哨兵来监控与自动处理故障, 一旦发现问题能做出相应的应对处理, 其功能包括:
注意: 因为哨兵模式 基于主从模式, 所以开启哨兵模式之前, 需要 先开启主从模式
- 监控
master、slave是否正常运行 - 当
master出现故障时, 能自动将一个slave转换为master - 多个哨兵可以监控同一个
Redis, 哨兵之间也会自动监控
当哨兵与 master 建立连接后, 会定期 向 master 和 slave 发送 PING 命令 (1s一次); 如果被 PING 的数据库或节点超时未回复, 哨兵会认为其主观下线, 如果下线的是 master, 哨兵会向其他哨兵发送命令询问是否也认为该 master 主观下线, 当一定数量的哨兵都认为该 master 主管下线后, 哨兵会认为该 master 已经客观下线
当哨兵认为 master 客观下线时, 故障恢复的操作需要由选举的领头哨兵来执行, 选举通过 Raft 算法: 即发现 master 的哨兵节点向每个哨兵发送请求, 要求对方选自己为领头哨兵, 如果目标哨兵节点没有选过其他人, 则会同意当前请求; 如果超过一半的哨兵同意, 则发送请求的哨兵节点当选为领头哨兵; 如果多个哨兵节点同时参选, 可能存在一轮投票后无竞选者胜出, 此时每个参选的节点等待一个随机时间后再次发起参选请求, 直到选出领头哨兵
选举出 领头哨兵 后, 会从下线的 master 的从库中挑选出一个当做新的 master ; 挑出需要继任的 slave 后, 领头哨兵 向该数据库发送命令使其升格 为master, 然后再向其他 slave 发送命令接受新的 master, 最后更新数据. 将已经停止的旧的 master 更新为新的 master 的从库, 使其恢复服务后以 slave 的身份继续运行
为了模拟较为真实的生产环境, 多加两台虚拟机作为哨兵使用:
安装 redis-sentinel
1 | $ sudo apt-get install redis-sentinel -y |
修改两台 sentinel 机器配置: sudo vim /etc/redis/sentinel.conf
1 | bind 0.0.0.0 # 绑定监听的IP 0.0.0.0允许所有IP访问 |
重启 redis-sentinel 服务之后, 可以通过 redis-cli -p 26379 连接到节点查看状态

在 master 执行以下命令关闭 redis-server 模拟 master 挂掉的场景, 然后进入 slave 中执行 info replication 查看两台 slave 的状态
1 | $ sudo systemctl stop redis-server |
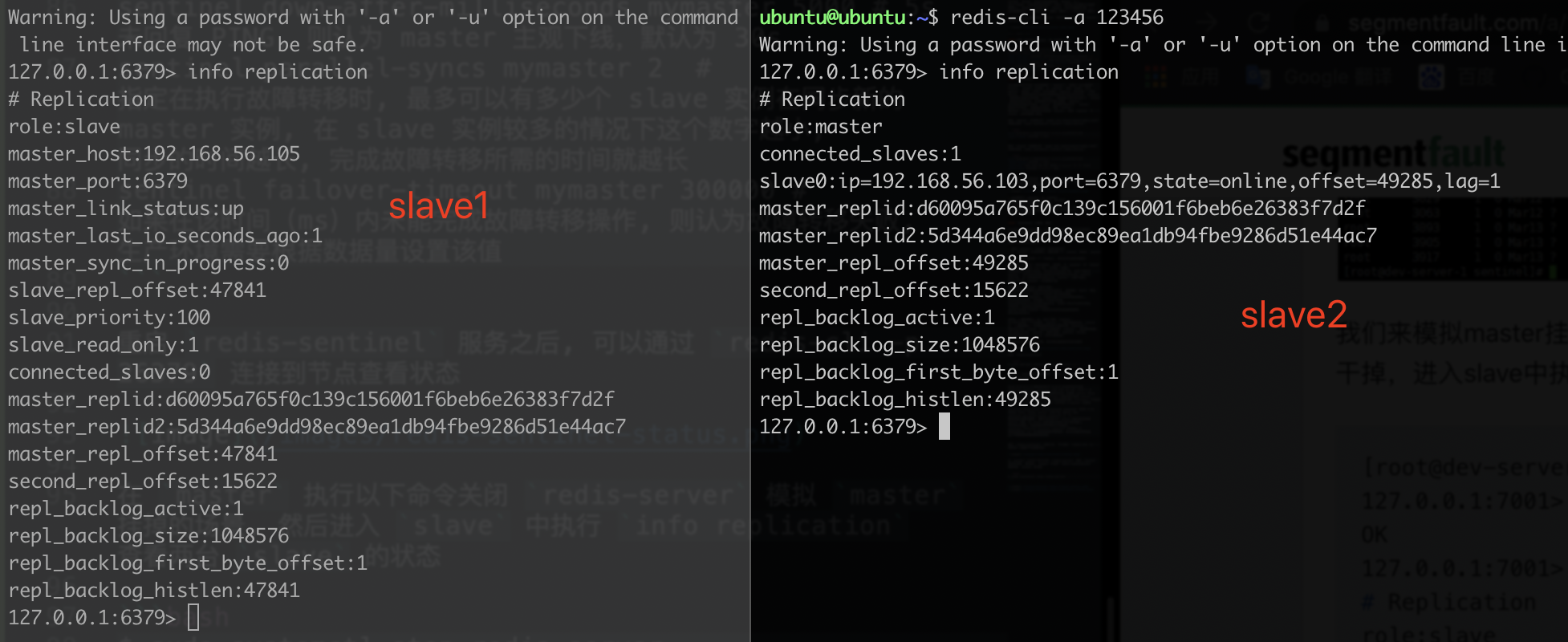

杀死 master 后, 可以查看 slave 的状态可以看到, slave2 这台机器已经继任成了主库, 两台 sentinel 的对应的主库已经从 192.168.56.102 变成了 192.168.56.105
哨兵模式 基于主从模式, 但是相较于主从模式在
master意外宕机后, 可以自动切换, 系统可用性更高
但是, 存在和组从模式存在一样的问题: 难以在线扩展、Redis容量受单机限制; 并且, 需要额外的资源来启动Sentinel服务, 实现相对于复杂
Cluster 模式
哨兵模式解决了主从复制不能自动故障转移, 达不到高可用的问题, 但还是存在难以在线扩容, Redis 容量受限于单机配置的问题. Cluster 模式实现了 Redis 的 分布式存储, 即每台节点存储不同的内容, 来解决在线扩容的问题
Cluster 采用无中心结构, 所有的 Redis 节点彼此互联( PING 机制), 节点是否失效是通过集群中超过半数的节点检测失效时才生效. 客户端与 Redis 节点直连, 不需要中间代理层. 客户端不需要连接集群所有节点, 只需要连接集群中任何一个可用节点
Cluster模式采用分布式存储, 在每个节点上, 都有一个插槽 (slot), 取值范围为 0-16383. 当存取key时, 节点会根据CRC16的算法得出一个结果, 然后把结果对 16384 求余, 求得的余被用来确定对应的数据存储在哪个节点中, 集群中的每个节点都存储了一份类似路由表的东西, 描述每个节点所拥有的Slots; 当用户请求一个不在请求节点的key时, 它可以根据这个路由表找到正确的服务节点, 告知用户正确的服务节点
Cluster模式集群节点最小配置 6 个节点(3 主 3 从, 因为需要半数以上), 其中主节点提供读写操作, 从节点作为备用节点, 不提供请求, 只作为故障转移使用。
修改所有机器的配置文件 sudo vim /etc/redis/redis.conf
1 | bind 0.0.0.0 # 绑定监听的IP 0.0.0.0允许所有IP访问 |
修改完所有机器的配置文件后, 使用 redis-cli 启动集群
1 | $ redis-cli --cluster create --cluster-replicas 1 192.168.56.102:6379 192.168.56.103:6379 192.168.56.105:6379 192.168.56.106:6379 192.168.56.107:6379 192.168.56.108:6379 -a 123456 |